2025-12-10
AIR 科研|Fast Training-free Perceptual Image Compression:1 分钟 → 0.1 秒的“免训练”感知压缩增强
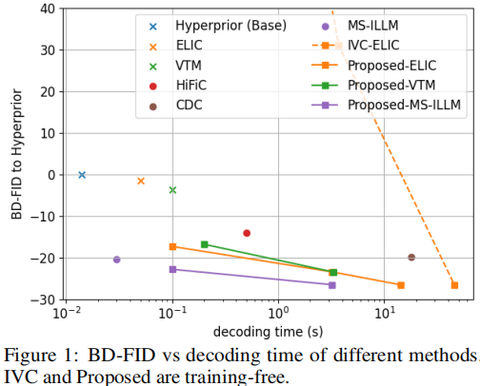
清华大学 AIR 联合多家机构提出一种 快速、免训练的感知图像压缩增强方法: 在不修改比特流和不重新训练生成模型的前提下,只在解码端增加一段 “加噪 + 去噪” 流程,即可显著提升任意现有编解码器的感知质量,同时将此前训练自由感知编解码器 动辄 1 分钟的解码时间,降到 0.1–10 秒量级。
2025-12-10
AIR 科研|Video-STR:用关系图和强化学习强化 MLLM 的视频时空推理
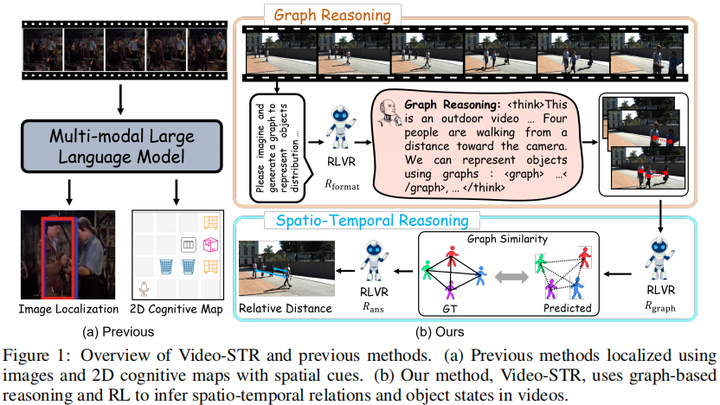
论文提出 Video-STR:面向多模态大模型(MLLM)的 视频时空推理强化框架。在现有 RLVR(Reinforcement Learning with Verifiable Reward)范式基础上,引入 “多目标关系图 + GRPO 强化学习”,显式建模视频中多个物体的空间拓扑与时间变化,并配套构建 STV-205k 大规模时空问答数据集。
2025-12-10
AIR 科研|Semore:VLM 引导的语义–运动表示,强化视觉强化学习
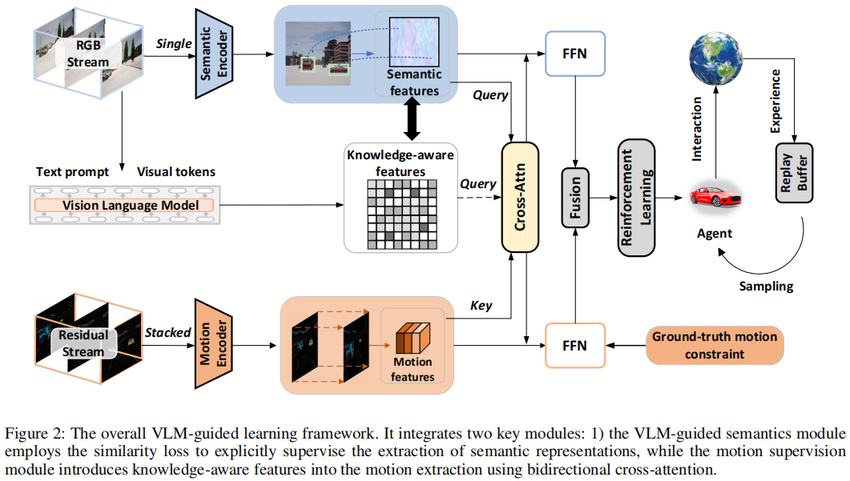
在视觉强化学习(visual RL)中,智能体需要从高维 RGB 图像中直接抽取状态表示并输出动作。传统方法往往只依赖自监督或世界模型等手段,缺乏对“哪些物体、哪些区域真正与当前任务相关”的显式先验
2025-12-10
AIR 科研|VRPSR:面向多种视频编码的重压缩感知感知超分辨
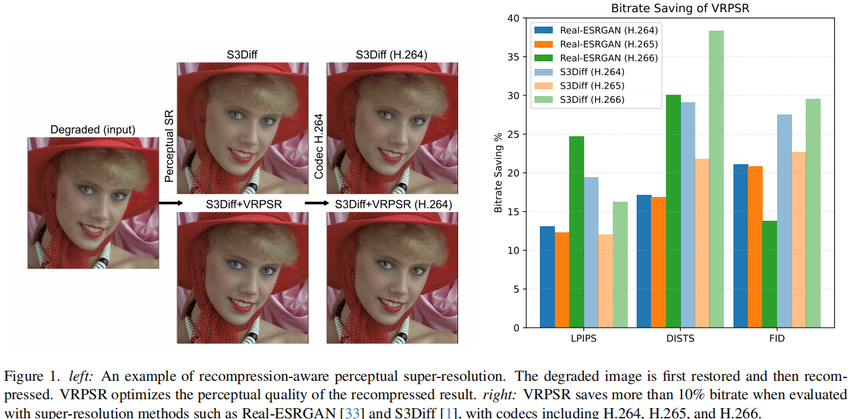
清华大学 AIR 联合多家机构提出 VRPSR(Versatile Recompression-Aware Perceptual Super-Resolution): 一个让现有感知图像超分辨(Real-ESRGAN、S3Diff 等)“感知下游重压缩”的通用框架。
2025-12-09
AIR 科研|Flow Planner:基于 Flow Matching的交互行为感知自动驾驶规划
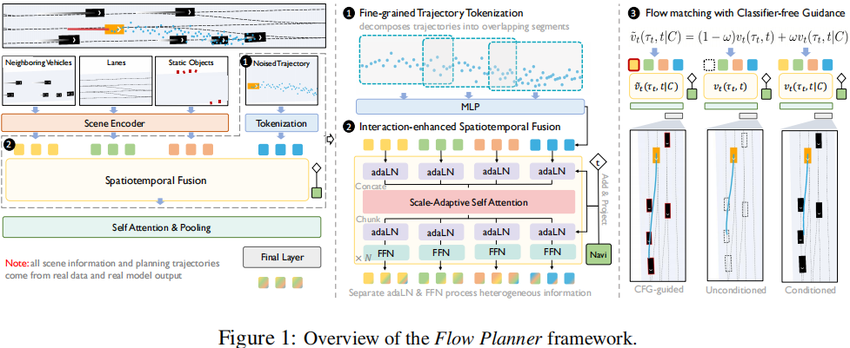
清华大学智能产业研究院(AIR)等提出 Flow Planner:一个基于 flow matching 的端到端自动驾驶规划框架,面向复杂场景中的 交互式驾驶行为建模。在 nuPlan 与 interPlan 等大规模闭环基准上,Flow Planner 在学习型规划器中取得新的 SOTA,并在“变道、路口抢行、绕行事故车、行人乱穿马路”等高交互场景中展现出更接近人类司机的行为策略。
2025-12-09
AIR 科研|SparseWorld 稀疏4D Occupancy世界模型,让世界建模更灵活高效
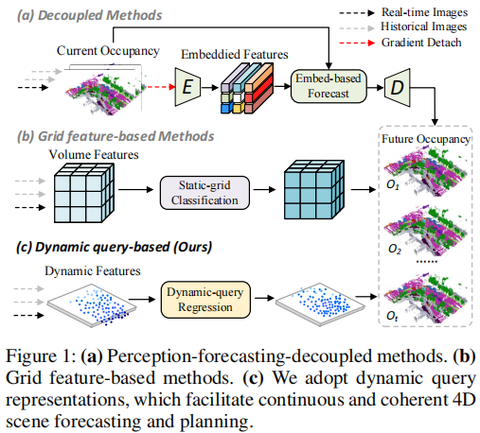
清华大学 AIR 联合多家高校与企业提出 SparseWorld:一个由 稀疏动态查询(sparse & dynamic queries)驱动的 4D occupancy 世界模型。
